
Online Help
Text Comparison - General Options
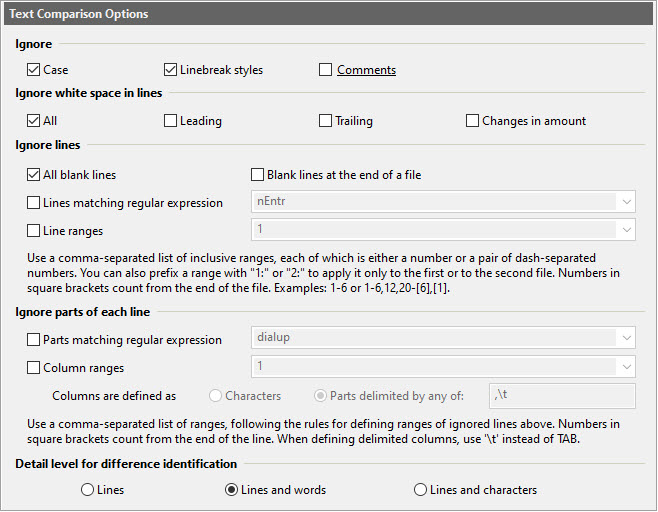
Dialog Box Options
IgnoreWhen parts of a text file are ignored, they are not compared. These options in this
section, as well as the Ignore white space in lines, Ignore lines,
and Ignore parts of each line sections, can be quickly disabled/enabled
with the Use Ignores command.
- Case
Consider upper- and lower-case to be the same.
- Linebreak styles
Ignore linebreak styles: CRLF (DOS/Windows) vs. LF (Unix) vs. CR (Mac).
- Comments
Ignore comments, as defined by the document type in use. Alternatively, you can use the Ignore Comments toolbar button
 .
.
- All
Ignore all white space in lines.
- Leading
Ignore leading white space in lines.
- Trailing
Ignore trailing white space in lines.
- Changes in amount
Ignore changes in the amount of white space in lines.
- All blank lines
Ignore changes whose lines are all blank.
- Blank lines at the end of a file
Ignore changes whose lines are all blank if they are at the end of a file.
- Lines matching regular expression
Ignore changes whose lines all match a specified regular expression.
- Row ranges
Ignore all lines whose line number falls within specified ranges. Use a comma-separated list of individual ranges, each of which is either a single number or a pair of hyphen-separated numbers. You can also prefix a range with "1:" or "2:" to apply it only to the first or to the second file (by default ranges apply to both files). Examples:
- 2-7
- 1:1-6,2:12,20-[6]
- [m]-n is not a valid string, for any integers m and n.
- Parts matching regular expression
Ignore, in each line, parts matching a specified regular expression. For instance, specifying //.* as a regular expression will make ExamDiff Pro ignore all single-line C++-style comments.
- Column ranges
Ignore, in each line, all text in specified ranges of columns. Use a comma-separated list of individual ranges, each of which is either a single number or a pair of hyphen-separated numbers. You can also prefix a range with "1:" or "2:" to apply it only to the first or to the second file (by default ranges apply to both files). See examples above under the description for Row ranges.
Note that columns can be defined as single characters, in which case you will be ignoring ranges of characters in each line, or as line parts delimited by any of specified characters (by default, comma or tab). The latter allows you to ignore columns in comma- or tab- (or any other character of your choice) delimited files.
View differences down to word or character level. Thus, if one letter
is changed in a file, then you can choose whether only the line of the change
is identified, the line and the word where the change occurred, or the line
and the character where the change occurred. Alternatively, you can use the
Detail Level drop-down toolbar button  .
.
.
Copyright © 1997-2025 PrestoSoft LLC. All rights reserved.