
Online Help
Text Comparison - Advanced Options
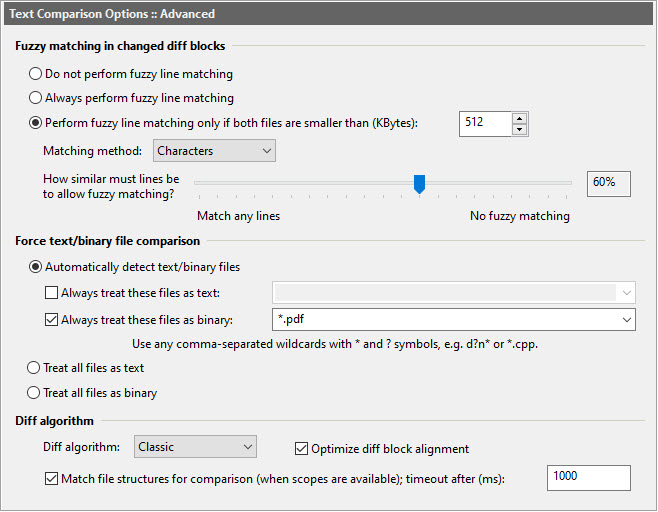
Dialog Box Options
Fuzzy matching in changed diff blocksFuzzy matching enables ExamDiff Pro to intelligently align lines in changed blocks that are similar but not identical. The options in this section control when fuzzy matching is activated and how selective it is.
- Do not perform fuzzy matching
Selecting this option always disables fuzzy matching.
- Always perform fuzzy matching
Selecting this option always enables fuzzy matching. This option is not recommended if you are comparing huge files, as it can potentially greatly slow down comparison.
- Perform fuzzy matching only if both files are smaller than
Selecting this option enables fuzzy matching only if the files compared are both smaller than the specified size (250KB by default).
- Matching method
Use this option to control how the matching of similar lines is performed. The default is Characters, and it suitable for most uses. Choose Words if your files have many distinguishable words.
- How similar must lines be to allow fuzzy matching?
This option determines the percentage similarity that two lines must have in order to be aligned if fuzzy matching is turned on. Keep in mind that if a line has multiple potential matches within a diff block, the match will be selected that maximizes the total similarity of all the fuzzy matches in the block. Our users typically find a threshold between 40% and 80% to be effective in producing the clearest alignments for most use cases.
Selecting 100% similarity ("No fuzzy matching") effectively disables fuzzy matching, because only exactly identical lines could be fuzzy-matched. Since changed blocks have no pairs of identical lines, no fuzzy matching will occur.
Selecting 0% similarly ("Match any lines") will align the lines in each block maximize the total similarity of all the fuzzy matches in the block, even if this configuration results in some lines being matched with completely dissimilar lines.
- Automatically detect text/binary files
Allow ExamDiff Pro to determine whether the compared files are text or binary.
- Always treat these files as text
Files matching any name filter in this comma-separated set will always be treated as text files.
- Always treat these files as binary
Files matching any name filter in this comma-separated set will always be treated as binary files, unless they also match one of the filters in the Always treat these files as text set (text takes precedence over binary).
- Always treat these files as text
- Treat all files as text
Compare all files as text and show the results in text format.
- Treat text files as binary
Compare all files as binary and show the results in HEX format.
-
Diff algorithm
This option is intended for advanced users only. You can use it to choose between six different diff algorithms.
The Classic diff algorithm is the algorithm used in ExamDiff Pro prior to version 12.0. It's a variation of the Myers algorithm.
The next four algorithms (Myers, Minimal, Patience, and Histogram) are implemented by the LibXDiff open-source library.
In general, we have found that ExamDiff Pro's Classic algorithm (which is itself a heavily modified version of Myers) gives the best results in most situations, but it's possible that one of the alternative diff algorithms could give you better results in some cases. This paper by Nugroho, Hata, and Matsumoto gives a good overview of the Myers, Minimal, Patience, and Histogram algorithms, and this blog post by Lup Peng offers some examples of when each of these four algorithms can be helpful.
Finally, in line-by-line comparison every line is matched to the line at the same position in the opposite file (i.e. line 50 in the first file will match with line 50 in the second file, ignoring their contents.) One exception is if manual synchronization links are used, in which case line-by-line comparison will be broken up by the links.
-
Optimize diff block alignment
With this option turned on, ExamDiff Pro uses a heuristic for determining the boundaries of diff blocks, based on the open-source work done in diff-slider-tools.
-
Match file structures for comparison (when scopes are available)
With this option turned on, ExamDiff Pro will automatically create links between the start and end lines of structures such as functions, classes, etc, that match between the two files, using a heuristic based on the structure "signature" (i.e. function signature, class signature, etc) to determine whether two structures are "matching".
The links that are automatically created by this feature act similarly to fuzzy-matching links (see above) but take precedence over them. You can view these links by enabling the Display | Show fuzzy/structure links option.
Note that this option only takes effect when all of the following conditions hold:- there are two files being compared or two-way merged (i.e. three-way merge mode is not being used)
- the two files being compared have the same document type, and their document type supports scope handling (i.e. "Participate in scope bar" is checked)
- the diff algorithm (see above) is not set to "line-by-line comparison"
Copyright © 1997-2025 PrestoSoft LLC. All rights reserved.